.svg)

.svg)
.svg)
LDA Topic Modelling: Theory, Implementation, Real-world Use Cases


Latent Dirichlet Allocation (LDA) is a probabilistic technique used in topic modelling. It works by assuming that each document is made up of multiple topics, and each word in the document can be attributed to one of these topics.
The significance of LDA in topic modelling is seen in its capacity to identify underlying themes in a document. It helps reveal hidden patterns within documents that are crucial for drawing insights from large datasets.
Some of the key terms associated with LDA are:
- Topics: The sets of words that co-occur frequently across documents.
- Word distributions: The probability of distribution over words for each topic.
- Documents: A mixture of topics.
Let’s dive deeper into the concepts of LDA topic modelling.
Theoretical Foundation of LDA
LDA topic modelling relies on the probabilistic generative process to perform various tasks like document clustering or generating customer recommendations. The probabilistic generative process works by making assumptions that each document is a mixture of topics and that each word in the document belongs to one of these topics.
It helps the algorithm generate a diverse range of documents depending on underlying topic distributions.
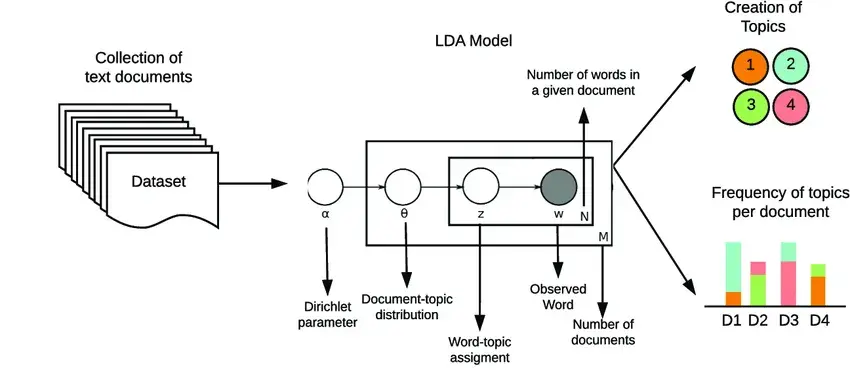
In LDA, Dirichlet Distribution is responsible for:
- Representing the distribution of topics within a document.
- Representing the distribution of words in the topics.
Dirichlet Distribution determines the probability of different topic mixtures in a document and the probability of word distributions within topics. It helps the algorithm shape the overall structure of the topic model.
When the LDA model needs to conduct iterations to properly map the topics, it uses Gibbs Sampling. This is an iterative method used for estimating hidden variables by repeatedly updating each topic assignment depending on the current assignments of other words.
The sampling happens from conditional distributions which provide probabilistic estimates for topic assignments.
Step-by-step Implementation of LDA
You can implement Latent Dirichlet Allocation in the three steps that are described below:
1. Dataset Selection and Preprocessing
The data selection and preprocessing step is an essential part of LDA as it focuses on preparing the text data for analysis. It is achieved in three steps:
(a) Importing Libraries
Load all the necessary libraries like NLTK (Natural Language Toolkit) or Gensim necessary for topic modelling. These libraries contain components that can be used for tasks like indexing, topic modelling, document retrieval, and more.
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
# Downloading NLTK resources
nltk.download('punkt')
nltk.download('wordnet')(b) Data Cleaning
In the second step, the LDA topic modelling algorithm loads and cleans all the data to remove noise and irrelevant information. It helps enhance the quality of information in the document, which helps with better text analysis and topic modelling results.
def load_and_clean_text_data(text_data):
# Your code to load and clean text data goes here
return cleaned_text_data(c) Tokenization, Lemmatization
In the third step, the algorithm tokenizes the text, which involves breaking down the entire text into individual words. It then uses lemmatization to reduce the words to their base form, which is crucial for aiding better text analysis.
def tokenize_and_lemmatize(text):
# Tokenization
tokens = word_tokenize(text)
# Lemmatization
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in tokens]
return lemmatized_tokensThe data preprocessing step essentially prepares the text extracted from a document for analysis.
2. Building the LDA Model
The next step involves building the topic model as described in the steps below:
(a) Creating a Document-Term Matrix (DTM)
The DTM is a representation of text-based data where each row corresponds to documents, and each column to unique terms or words. Each cell in the matrix carries the frequency of a term in a document.
from gensim import corpora, models
def create_document_term_matrix(text_data):
# Your code to create document-term matrix goes here
return dtm(b) Setting Parameters
This step involves setting parameters like the number of topics, alpha, and beta. Number of topics is a key parameter that impacts the granularity and interpretability of the extracted topics.
On the other hand, alpha and beta are hyperparameters that control the sparsity of document-topic distribution (alpha) and topic-word distribution (beta). To achieve optimal model performance, it is necessary to finetune these parameters.
num_topics = 5
alpha = 'auto'
beta = 'auto'(c) Training the LDA Model
This step involves training the LDA model using the DTM created in the first step. The model then iteratively assigns words to topics and topics to documents until it reaches convergence where these assignments are stable.
def train_lda_model(dtm):
# Building LDA model
lda_model = models.LdaModel(dtm, num_topics=num_topics, id2word=dictionary, alpha=alpha, eta=beta)
return lda_model3. Analyzing LDA Results
The third and final step of LDA topic modelling implementation involves analysis of the results delivered by the model. This is done by following these steps:
(a) Extracting Topics and Their Word Distributions
This step involves the analysis of top words and their associated topics based on their probabilities. It helps identify the prominent terms to understand the themes that are represented by topics, delivering insight into the content.
Here is a Python code snippet example:
def extract_topics(lda_model):
topics = lda_model.print_topics(num_topics=num_topics, num_words=10)
return topics(b) Assigning Topics to Documents
This step involves assigning a distribution of topics to documents depending on the prevalence of topic-related words they contain. It helps to understand the overall distribution of topics across the textual data and the thematic composition of individual documents.
Let's look at a Python snippet:
def assign_topics_to_documents(lda_model, dtm):
document_topics = lda_model.get_document_topics(dtm)
return document_topics(c) Visualizing Topic Distributions
This step involves visualization of the topic distributions using heatmaps, bar charts, interactive dashboards, and other visualization techniques. It helps in understanding the topic distribution better and establishing relationships between topics, which facilitates the interpretation of the results achieved.
Here is a Python snippet:
def visualize_topic_distributions(document_topics):
# Your code to visualize topic distributions goes here
passEvaluation Metrics for LDA
There are several evaluation metrics that you can use for LDA topic modelling to gauge its performance and accuracy:
1. Perplexity Score
The perplexity score is a representation of the level of uncertainty or confusion in the topic model’s predictions. A lower perplexity score indicates that the model is performing well. This metric is commonly used to measure the quality of a topic model and for informing parameter optimization.
2. Coherence Score
The coherence score is the quantification of semantic coherence of topics, which measures the degree of association between words within each topic. It is used to quantify how meaningful and interpretable the topics are by measuring how similar the words contained in them are. A high coherence score indicates the presence of more coherent and meaningful topics.
3. Topic diversity
This metric measures the spread of topics across documents. A higher diversity indicates topics that cover a larger range of documents.
4. Topic consistency
This metric measures the stability of topics over multiple iterations. Higher consistency indicates reliable topic modelling results.
5. Topic interpretability
This metric measures how easily a user can understand and interpret the topics that the model has generated. High interpretability indicates the presence of more meaningful topics.
Real-world Applications and Use Cases
LDA topic modelling has vast applications across various industries:
1. Identifying Topics in News Articles
LDA algorithms analyse news articles to identify underlying themes or topics in the text. They extract keywords or phrases that represent various topics, which allows for categorization and enhanced organization of articles.
This process is crucial for summarizing large volumes of news data to identify trends across various topics.
2. Analyzing Customer Reviews for Product Improvement
LDA topic modelling can be applied to customer reviews to extract topics that are related to product features, services or other brand attributes.
LDA identifies the common theme and sentiment across customer reviews, helping businesses gain insight into the preferences and satisfaction levels of their customers. Brands can also identify areas for improvement using LDA topic modelling.
3. Extracting Themes from Academic Research Papers
LDA topic modelling is used to identify recurring research themes or subject areas across a large volume of research papers or other academic documents.
It helps analyse and organize huge corpora of academic papers, uncovering knowledge gaps, areas of interest within a discipline or field, and more.
Challenges and Best Practices in LDA
LDA topic modelling does have its challenges. However, they can be easily addressed by following certain best practices:
1. Addressing Overfitting and Underfitting
Overfitting and underfitting are common challenges in topic modelling. Overfitting occurs when the model captures noisy data in the results, and underfitting occurs when the model is too simple to catch the structure in the textual data.
One best practice to avoid overfitting or underfitting your model is to use regularization techniques. Adjustment of hyperparameters can address overfitting. On the other hand, you can increase model complexity to address underfitting.
2. Optimizing Model Performance with Proper Parameter Tuning
It can be a challenge to optimize model performance as it includes finding the right balance between interpretability and model complexity. Finetuning the hyperparameters (alpha, beta) can pose difficulties.
However, you can use cross-validation techniques to assess model performance and to systematically explore the best parameter combinations.
3. Handling Large and Noisy Datasets
Large and noisy datasets pose the risk of making the model computationally complex and less accurate.
To address the challenge of noisy data, establish detailed data preprocessing steps to remove irrelevant documents, removing stop words, punctuation, etc. You can also use parallel processing and efficient data structures to manage memory usage and enhance performance and model scalability.
Conclusion
LDA topic modelling is a crucial tool that enterprises use for a variety of tasks, such as creating recommendation systems and document classifications. You can implement LDA models in three steps: selecting the dataset and preprocessing, building the model, and analysing the performance.
LDA can be used for various other tasks that involve text-based datasets to enhance operational efficiencies in tasks like extracting insights and patterns from documents. If your business is looking to build and implement your own LDA topic modelling tool, you need a robust AI framework that provides you with the right foundation to build on.
Markov’s AI-based platform functions as the plinth on which you can build all your AI-powered tools such as data intelligence systems that use LDA topic modelling. You can discover hidden insights from your textual data using no-code Auto EDA solutions, and use Intelligent Data Catalog to effortlessly organize all your data.
Explore Markov and its full suite of solutions today.
Kankona Das
Content Marketing at MarkovML
Let’s Talk About What MarkovML
Can Do for Your Business
Boost your Data to AI journey with MarkovML today!